数据探索性分析
意义
目的在于熟悉、了解数据集,对数据集进行验证来确定所获得的数据集可以用于后续的机器学习或深度学习使用。
进一步了解变量间的相互关系以及变量与预测值之间的存在关系。
引导进行数据处理以及特征工程的步骤,使数据集的结构和特征集让预测更合理。
对数据进行一些图表或文字总结。
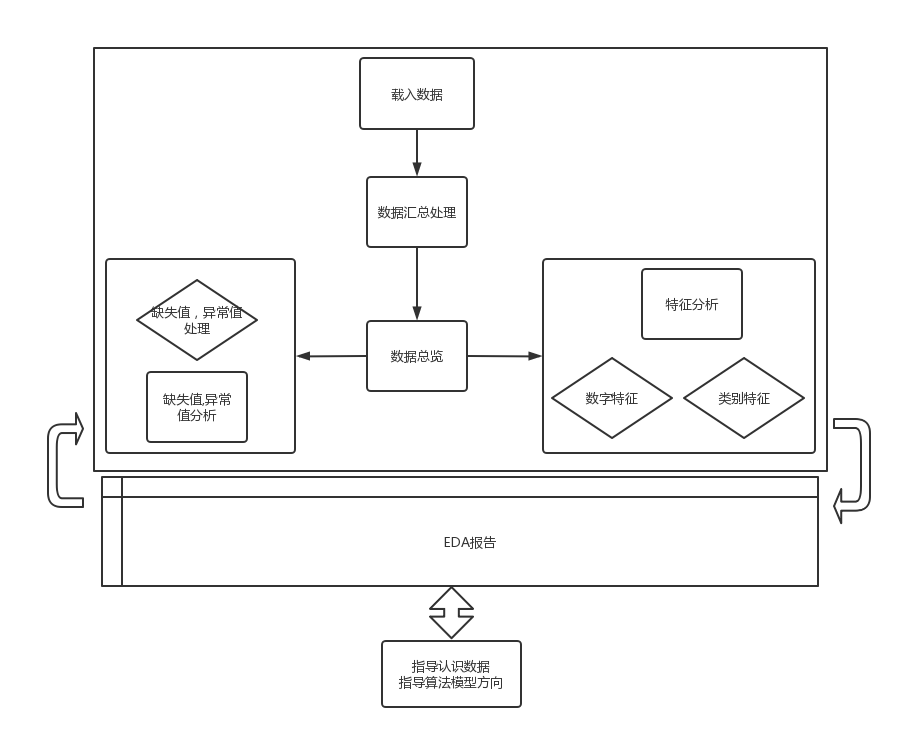
1. 载入数据
目的:从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据到我们程序中。以便对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征等行为。
# pandas.read_csv
# 可以读取CSV(逗号分割)文件、文本类型的文件text、log类型到DataFrame
test_data = pd.read_csv(path, sep=' ')
train_data = pd.read_csv(patn , sep=' ')
# pandas.read_excel
# 可以读取表格文件
pd.read_excel('文件名.xlsx', sheet_name='表名')
# Pandas读取数据库
import pymysql
import pandas as pd
# 连接数据库为test
conn=pymysql.connect(host="127.0.1",user="root",passwd="1234",db="test")
# 查询的表为students
sql="select * from students"
data=pd.read_sql(sql,conn)
# Pandas读取html文件
htl=pd.read_html('E:\test.html')
2. 数据汇总处理
目的:虽然从数据包中获取了大量的基础数据。然而,丰富的数据资源由于建设时期不同,开发部门不同、使用设备不同、技术发展阶段不同和能力水平的不同等因素,导致数据的结构,数据的记录方式会有不一致性。这就使得数据资源难于同一套脚本查询访问,数据不能直接比较分析。数据汇总合并就是采用一种通用的标准和规范,将有结构不一致性的数据源,整合成一致的,可用度高的数据。
直接合并/堆叠合并
左右合并
pd.concat( (df1,df2), aixs=1)
合并结果(在列的方向直接合并,取所有的列名称(重复不补合并),在行的方向,根据连接方式决定join=inner; 取行索引的交集,join=outer; 取行索引的并集)
上下合并
pd.concat( (df1,df2), aixs=0)
df1.append(df2)
合并结果:(在行的方向直接合并,取所有的行名称(重复行不合并),在列的方向,根据连接方式决定join=inner; 取列索引的交集,join=outer; 取列索引的并集)
场景:通常用于列索引一致的情况下。
缺点:以索引作为参考
主键合并
pd.merge(left=df1, right=df2, on="", how="")
仅能实现左右合并,on=”” 主键,可以是一个主键,也可多个主键; left_on,right_on。how=”inner”、outer、left、right。
重叠合并
df1.combine_first(df2)
df1是主表,目的:两个不完整的表,合成一张相对完整的表。将主表的空值,用其他表中的非空值填充。
3. 数据总览
目的:对最终合并好的数据有一个前瞻性,大体性的认识。索引和列的数据类型和占用内存大小。对数值型数据生成描述性统计汇总,包括数据的计数和百分位数,分类型数据中每个类的数量,了解数据的大致分布。
dataframe.head() # 查看数据前5行
data.info() # 查看数据的信息,包括每个字段的名称、非空数量、字段的数据类型:
data.describe() # 查看数据的统计概要(count/mean/std/min/25%/50%/75%max)
dataframe.shape # 查看dataframe的大小
# 按列/数组排序
df.groupby(['列名']).cumcount() # 按某列排序:正序(倒序)
sort_values(by="列名/行名") # 对该列或该行进行值排序
numpy.argsort(a) 或者 a.argsort() # 对数组进行升序排序,返回索引值。降序的话可以给a加负号。
# 数据相加
a.sum(axis=1) # a为数组,sum(axis=1)表示每行的数相加,平时不加axis则默认为0,为0表示每列的数相加。
# 字典操作
# sorted对字典或者列表的后面一个值排序
sorted(dic.items() , key=lambda x:x[1] , reverse=True )
sorted(dic.items(), key=operator.itemgetter(1) , reverse=True)
# 字典的get函数
dic.get(key,0) # 相当于if ……else ,若key在字典dic中则返回dic[key]的值,若不在则返回0
4. 缺失值分析
目的:在各种数据中,属性值缺失的情况经常发全甚至是不可避免的。因此,在大多数情况下,信息系统是不完备的,或者说存在某种程度的不完备。数据或多或少都会存在缺失值,不仅包括数据库中的NULL值,也包括用于表示数值缺失的特殊数值(比如,在系统中用-999来表示数值不存在)。如果我们仅有数据库的数据模型,而缺乏相关说明,常常需要花费更多的精力来发现这些数值的特殊含义。而如果我们漠视这些数值的特殊性,直接拿来进行挖掘,建模那么很可能会得到错误的结论。因此在之前的阶段进行数据缺失值分析很重要。
dataframe.isnull()
# 元素级别的判断,把对应的所有元素的位置都列出来,元素为空或者NA就显示True,否则就是False
dataframe.isnull().any()
# 列级别的判断,只要该列有为空或者NA的元素,就为True,否则False
missing = dataframe.columns[ dataframe.isnull().any() ].tolist()
# 将为空或者NA的列找出来
dataframe [ missing ].isnull().sum()
# 将列中为空或者NA的个数统计出来
len(data["feature"] [ pd.isnull(data["feature"]) ]) / len(data))
# 缺失值比例
msno.matrix(train_data.sample(300))
msno.bar(train_data.sample(1000))
# 可视化看下缺省值
5. 缺失值处理方式
# 直接删除含有缺失值的行/列:
new_drop = dataframe.dropna ( axis=0,subset=["Age","Sex"] )
# 【在子集中有缺失值,按行删除】
new_drop = dataframe.dropna ( axis=1)
# 【将dataframe中含有缺失值的所有列删除】
# 插补:
# a, 固定值插补
dataframe.loc [ dataframe [ column ] .isnull(),column ] = value # 将某一列column中缺失元素的值,用value值进行填充。
# b, 均值插补
data.Age.fillna(data.Age.mean(),inplace=True) # 将age列缺失值填充均值。(偏正态分布,用均值填充,可以保持数据的均值)
# c, 中值插补
df['price'].fillna(df['price'].median()) # 偏长尾分布,使用中值填充,避免受异常值的影响。
# d, 最近数据插补
dataframe ['age'].fillna(method='pad') # 使用前一个数值替代空值或者NA,就是NA前面最近的非空数值替换
dataframe ['age'].fillna(method='bfill',limit=1) # 使用后一个数值替代空值或者NA,limit=1就是限制如果几个连续的空值,只能最近的一个空值可以被填充。
# e, 回归插补
from scipy.interpolate import interp1d # 线性关系插值
# f, 拉格朗日插值
from scipy.interpolate import lagrange # 拉格朗日 【非线性插值】
# g, 牛顿插值法
# h, 分段插值
# i, K-means
# 通过K均值的聚类方法将所有样本进行聚类划分,然后再通过划分的种类的均值对各自类中的缺失值进行填补。归其本质还是通过找相似来填补缺失值。缺失值填补的准确性就要看聚类结果的好坏了,而聚类结果的可变性很大,通常与初始选择点有关,因此使用时要慎重。
# g, KNN填补空值
# h, 时间类型
df.interpolate() # 对于时间序列的缺失,可以使用这种方法。
6. 异常值分析
目的:在数据准备的过程中,数据质量差又是最常见而且令人头痛的问题。数据质量差的根源一方面来自于缺失值,一方面也来自于存在很多的异常数据值。异常值的存在会降低训练模型的鲁棒性,异常值分析和处理之后模型的拟合性会提高。
查看异常值
# 画数据的散点图。观察偏差过大的数据,是否为异常值;
plt.scatter(x1,x2)
# 画箱型图,箱型图识别异常值比较客观,因为它是根据3σ原则,如果数据服从正态分布,若超过平均值的3倍标准差的值被视为异常值。
Percentile = np.percentile(df['length'],[0,25,50,75,100])
IQR = Percentile[3] - Percentile[1] # Ql为下四分位数:表示全部观察值中有四分之一的数据取值比它小;
UpLimit = Percentile[3]+ageIQR*1.5 # Qu为上四分位数:表示全部观察值中有四分之一的数据取值比它大;
DownLimit = Percentile[1]-ageIQR*1.5 # IQR称为四分位数间距:是上四分位数Qu和下四分卫数Ql之差,之间包含了全部观察值的一半。
# seaborn画boxplot
f,ax=plt.subplots(figsize=(10,8)) sns.boxplot(y='length',data=df,ax=ax) plt.show()
# 基于模型预测
# 构建概率分布: 离群点在该分布下概率低就视为异常点
#基于近邻度的离群点检测:
# KNN
# 基于密度的离群点检测:
# 对象到k个最近邻的平均距离的倒数,如果该距离小,则密度高;
# DBSCAN:一个对象周围的密度等于该对象指定距离d内对象的个数
# 基于聚类的方法来做异常点检测:
# K-means
# 专门的离群点检测:
# One class SVM和Isolation Forest
异常值处理方式
视为缺失值:修补(平均数、中位数等)
直接删除:是否要删除异常值可根据实际情况考虑。因为一些模型对异常值不很敏感,即使有异常值也不影响模型效果,但是一些模型比如逻辑回归LR对异常值很敏感,如果不进行处理,可能会出现过拟合等非常差的效果。
不处理:直接在具有异常值的数据集上进行数据挖掘
平均值修正:可用前后两个观测值的平均值修正该异常值
7. 数据特征分析
目的:在拿到清洗好的数据后,建模人员不知道从哪里开始了解目前拿到手上的数据,对于如何建模可能也没有头绪。在数据预处理阶段就可以进一步对数据特征进行分析。将各个字段下的数据进行分析,写入EDA报告中,为拿到数据后做建模提供方向性指导。
定量数据分布分析
# 相关性分析:
price_numeric = Train_data[numeric_features]
correlation = price_numeric.corr()
print(correlation['price'].sort_values(ascending=False))
# 相关性热力图:
f , ax = plt.subplots(figsize = (7, 7))
plt.title('title',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)
偏度和峰值
# 逐列查看偏度,峰值
for col in numeric_features:
print('{:15}'.format(col),
'偏度: {:05.2f}'.format(Train_data[col].skew()) ,
'峰值: {:06.2f}'.format(Train_data[col].kurt()))
分布可视化
f=pd.melt(Train_data,value_vars=numeric_features)
g=sns.FacetGrid(f,col="variable",sharex=False,harey=False)
g=g.map(sns.distplot, "value")
相互之间关系可视化
sns.set()
columns=['price','v_12','v_8','v_0']
sns.pairplot(Train_data[columns],size=2,kind='scatter',diag_kind='kde')
plt.show()
常见统计量
集中趋势度量:均值、中位数、众数
离中趋势度量:极差、标准差、变异系数(标准差/均值)、四分位数间距。
周期性
帕累托法则(即为二八法则)
8. 类别特征分析
类别特征的小提琴图可视化
catg_list = categorical_features
target = 'price'
for catg in catg_list :
sns.violinplot(x=catg, y=target, data=Train_data)
plt.show()
柱状图可视化
def bar_plot(x, y, **kwargs):
sns.barplot(x=x, y=y)
x=plt.xticks(rotation=90)
f = pd.melt(Train_data,id_vars=['price'],value_vars=categorical_features)
g = sns.FacetGrid(f,col="variable",col_wrap=2, sharex=False, sharey=False,size=5)
g = g.map(bar_plot, "value", "price")
常见统计量
频数,频率,众数,异众比率