模型可解释性
SHAP方法(黑盒模型事后归因解析)
Shapley Value
在当今的金融、医疗等数据挖掘的应用领域中,模型的可解释性和精度是同等的重要。众所周知,精度较高的模型,如集成模型,深度学习模型等,内部结构复杂多变,不能直观理解。SHAP,作为一种经典的事后解释框架,可以对每一个样本中的每一个特征变量,计算出其重要性值,达到解释的效果。该值在 SHAP 中被专门称为 Shapley Value。因此 Shapley Value 是 SHAP 方法的核心所在,理解好该值背后的含义将大大有助于我们理解 SHAP 的思想。
Shapley value 计算
可以通过一个小例子来看如何计算 Shapley Value。
假设:合作项目 Proj=<Players, v>
Players={1,2,…n}, 每个玩家在这个项目中所做的贡献量的特征方程是 v。
定义 Proj=500 行代码,由 3 个程序员完成,这就对应 3 个玩家:1,2,3。
每个玩家可以独立完成的代码:v(1)=100, v(2)=125, v(3)=50
如果合作:v(1,2)=270,v(2,3)=350, v(1,3)=375, v(1,2,3)=500。
具体的合作过程有 6 种情况:
玩家 1 邀请玩家 2, 玩家 2 接着邀请玩家 3;
玩家 1 邀请玩家 3, 玩家 3 接着邀请玩家 2;
玩家 2 邀请玩家 1, 玩家 1 接着邀请玩家 3;
玩家 2 邀请玩家 3, 玩家 3 接着邀请玩家 1;
玩家 3 邀请玩家 1, 玩家 1 接着邀请玩家 2;
玩家 3 邀请玩家 2, 玩家 2 接着邀请玩家 1;
用图来表示:
1
2
3
1
3
2
2
1
3
2
3
1
3
1
2
3
2
1
如果我们要合理分配,是否公平主要看边际贡献。
先定义第 i 个玩家加入组织 S 的边际贡献 delta(i)=v(S cup {i})-v(S)
挑选第一种情况为例:
玩家 1 边际贡献: v({1})=100
玩家 2 边际贡献: v({1,2})-v({1})=270-100=170
玩家 3 边际贡献: v({1,2,3})-v({1,2})=500-270=230
按照上面的计算过程,依次计算剩下的 5 种情况。同时考虑到这 6 种情况是等概率出现的。完整结果如下图:
概率
玩家加入顺序
玩家1的边际贡献
玩家2的边际贡献
玩家3的边际贡献
1/6
1,2,3
100
170
230
1/6
1,3,2
100
125
275
1/6
2,1,3
145
125
230
1/6
2,3,1
150
125
225
1/6
3,1,2
325
125
50
1/6
3,2,1
150
300
50
计算第 i 个玩家的 Shapley Value, 主要是由上图的边际贡献得到。
玩家
Shapley Value
1
(100+100+145+150+325+150)/6 = 970/6
2
(170+125+125+125+125+300)/6 = 970/6
3
(230+275+230+225+50+50)/6 = 1060/6
所以按照比例来分配奖金:
玩家 1 分配的奖金为总奖金的 32.3%
玩家 2 分配的奖金为总奖金的 32.3%
玩家 3 分配的奖金为总奖金的 35.3%
SHAP 原理
SHAP 全称是 SHapley Additive exPlanation, 属于模型事后解释的方法,可以对复杂机器学习模型进行解释。虽然来源于博弈论,但只是以该思想作为载体。在进行局部解释时,SHAP 的核心是计算其中每个特征变量的 Shapley Value。
SHapley:代表对每个样本中的每一个特征变量,都计算出它的 Shapley Value。
Additive:代表对每一个样本而言,特征变量对应的 shapley value 是可加的。
exPlanation:代表对单个样本的解释,即每个特征变量是如何影响模型的预测值。
当我们进行模型的 SHAP 事后解释时,我们需要明确标记。已知数据集(设有 M 个特征变量,n 个样本),原始模型 f,以及原始模型 f 在数据集上的所有预测值。g 是 SHAP 中用来解释 f 的模型。
先用 f 对数据集进行预测,得到模型预测值的平均值 \(\phi_0\) ,单个样本表示为 \(x=(x_1,x_2 ... x_M)\) , \(f(x)\) 为在原始模型下的预测值。 \(g(x)\) 是事后解释模型的预测值,满足 \(g(x) = \phi_0 + {\textstyle \sum_{i=1}^{M}}\phi_ix_i=f(x)\) 。其中 \(\phi_i\) 代表第 \(i\) 个特征变量的Shapley value,是SHAP中的核心要计算的值,需要满足唯一性。同时上述模型 \(g\) 需要满足如下的性质:
性质 1:局部保真性 (local accuracy)
即两个模型得到的预测值相等。当输入单个样本 \(x\) 到模型 \(g\) 中时,得到的预测值 \(g(x) = \phi_0 + {\textstyle \sum_{i=1}^{M}}\phi_ix_{i}^{'}\) 与原始模型得到的预测值 \(f(x)\) 相等
性质 2:缺失性 (missingness)
如果在单个样本中存在缺失值,即某一特征变量下没有取值,对模型 \(g\) 没有影响,其Shapley Value为0。
性质 3:连续性 (consistency)
当复杂模型f从随机森林变为XGBoost,如果一个特征变量对模型预测值的贡献增多,其Shapley value也会随之增加
在上述3个限制条件下,可以理论证明求出唯一的 \(\phi_0\) ,即对应的模型 \(g\) 也是独一无二的。具体可参考Shapley’s paper(1953)。
详细来说, \(N=\left \{ 1,2…M \right \}\) 代表数据集中特征变量下标,1代表第一个特征变量,以此类推,i是第i个特征变量,M是特征变量的总个数。S是集合 \(\left \{ 1,2…i-1,i,…M \right \} \) 种可能。 \(\left | S \right |\) 是S中元素的总个数。 \(\int_{x}=(S\cup i)\) 代表当样本中只有 \(S\cup i\) 中的特征变量值时,模型的预测值。 \(\int_{x}=(S)\) 代表当样本中只有 \(S\) 中的特征变量值时,模型的预测值。二者相减,可当成第i个特征变量在子集S下的边际贡献。前面的权重(kernel): \(\frac{\left | s \right |!(M-\left | s \right |-1)!}{M!}\) 是根据排列组合的公式得到,代表相同元素个数的S存在的概率。
SHAP 解释
解读Shapley Value如何影响原始模型f的预测值。假设数据集中有4个特征变量 \(z_1, z_2, z_3, z_4\) 用原始模型f预测之后,我们以模型预测值的平均值作为其期望 \(E(f(z))\) , 即 \(\phi_0\) 。以单个样本 \(x = (x_1, x_2, x_3, x_4)\) 为例,它在原始模型中的预测值为 \(f(x)\) ,我们计算出4个对应的Shapley Value \(\phi_1, \phi_2, \phi_3, \phi_4\) 后开始解释
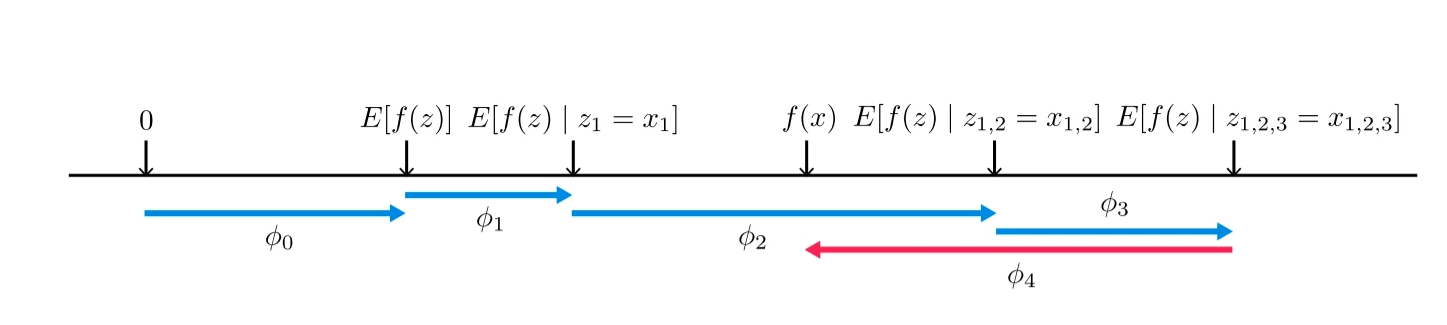
对于整个数据集而言, \(\phi_0\)phi_4 < 0 < phi_1 < phi_3 < phi_2` ,所以特征变量 \(z_1, z_2, z_3\) 对 \(f(x)\) 有正向的作用,且 \(z_2\) 的作用最强, \(z_4\) 的存在则对 \(f(x)\) 构成了负向的作用。最终在这4个特征变量的力的作用下,将该样本x的原始模型预测值从平均值达到了 \(f(x)\)