Usage
建模流程由以下五个环节组成:
1. 数据探索性分析
工作内容
加载原始的训练数据
样例代码
# 原始数据读取
logger.info("start data loading >>>>>>>>>" )
base_dir = os.getcwd()
logger.info("load dataframe >>>>>>>>>" )
credit_data = pd.read_csv(os.path.join(base_dir, r'../data/germancredit.csv'))
numeric_feats = credit_data.select_dtypes(include=['int64','float64']).columns.tolist()
category_feats = list(set(credit_data.columns) - set(numeric_feats + ['creditability']))
logger.info("The dataset has %s pieces of data, %s numeric_feats, %s category_feats >>>>>>>>>" %(len(credit_data),len(numeric_feats),len(category_feats)))
# 文字->数字映射
credit_data["flag"] = credit_data["creditability"].replace({"good": 0, "bad": 1})
logger.info("end data loading >>>>>>>>>" )
工作内容
- 培养对数据的直觉
对数据进行清洗
对数据进行描述(描述统计量,图表)
查看数据的分布
比较数据之间的关系
样例代码
# 数据探索性分析
logger.info("start EDA >>>>>>>>>" )
featurebox_plot(credit_data, columns=numeric_feats, sub_col=2, picture_name=base_dir+"/output/箱形图")
logger.info("箱形图完成")
featuredis_plot(credit_data, columns=numeric_feats, label='flag',sub_col=3, picture_name=base_dir+"/output/数值型特征分布图")
logger.info("数值型特征分布图完成")
featurecategory_plot(X=credit_data, columns=category_feats, label="flag", sub_col=13,picture_name=base_dir+"/output/类别型特征分布图")
logger.info("类别型特征分布图完成")
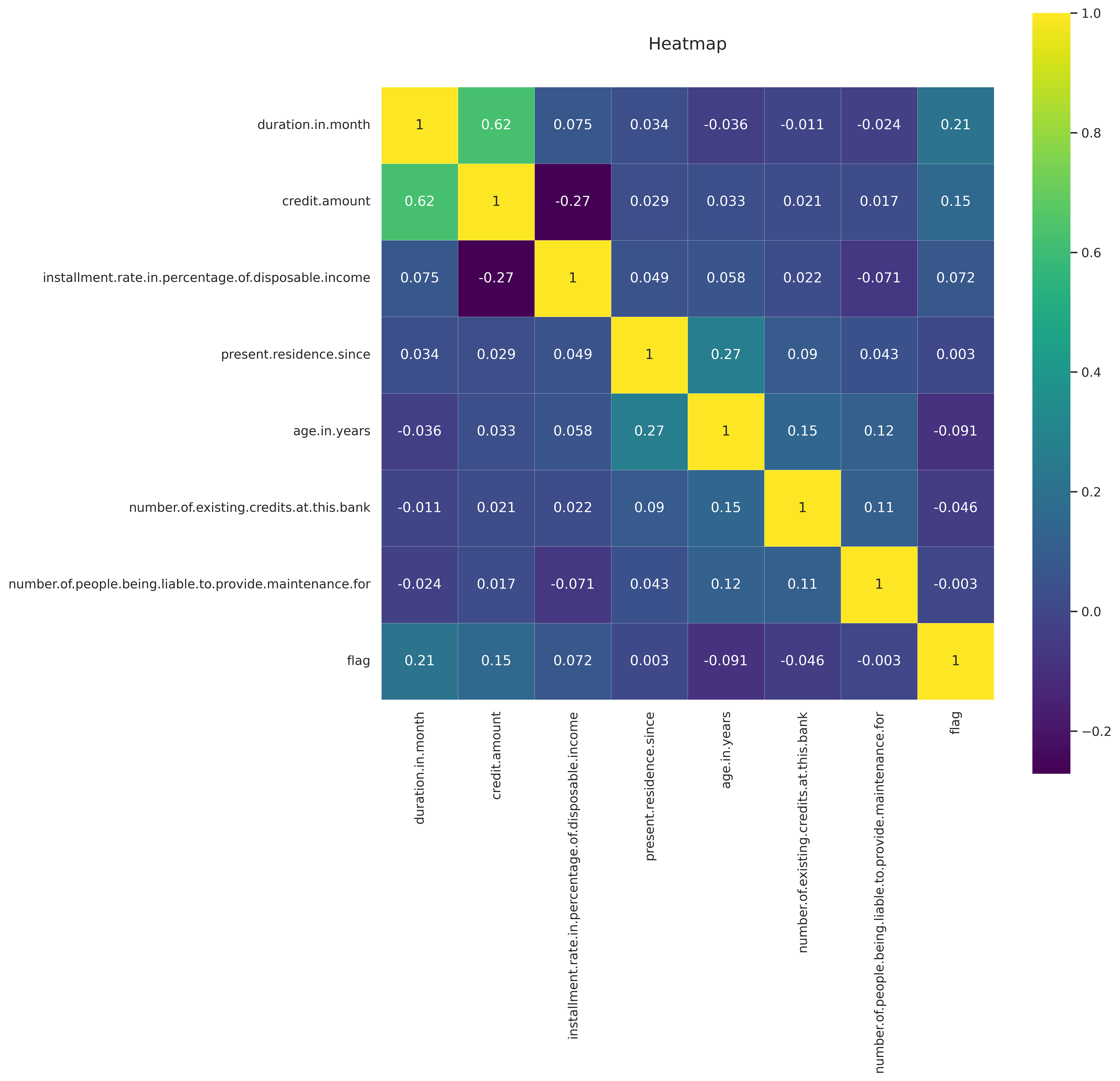
featurecor_plot(X=credit_data, columns=numeric_feats+['flag'],picture_name=base_dir+"/output/相关性热图")
logger.info("相关性热图完成")
with timer('detect dataframe', logger):
dec = DetectDF(credit_data)
df_des = dec.detect(special_value_dict={-999:np.nan}, savefolder = base_dir +'/output')
logger.info("数据探查统计表完成")
logger.info("end EDA >>>>>>>>>" )
模块明细
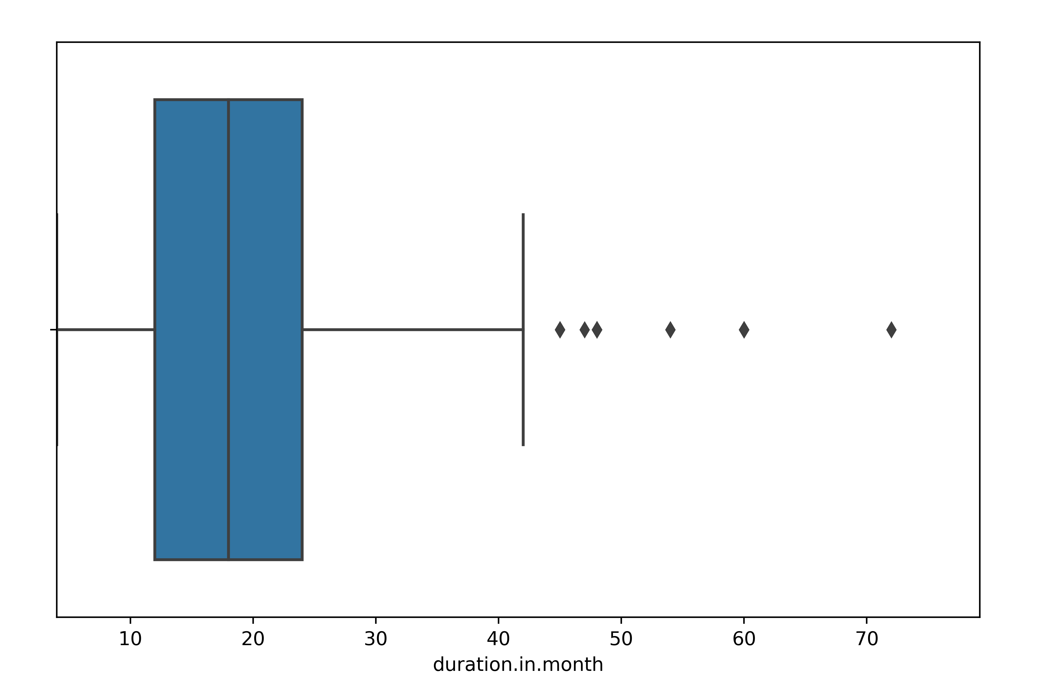
bm.visual.quick_visual.featurebox_plot()箱形图
显示出一组数据的最大值、最小值、中位数、及上下四分位数。
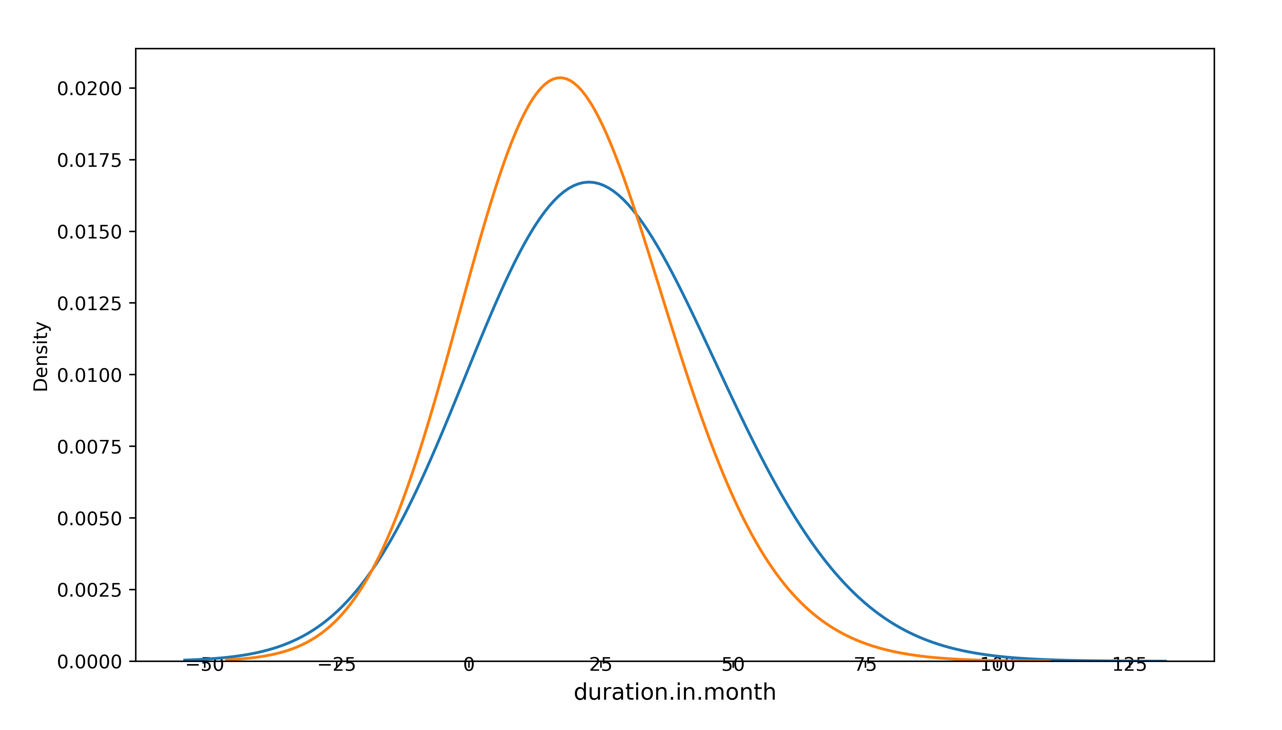
bm.visual.quick_visual.featuredis_plot()数值型特征分布图
查看特征分布情况
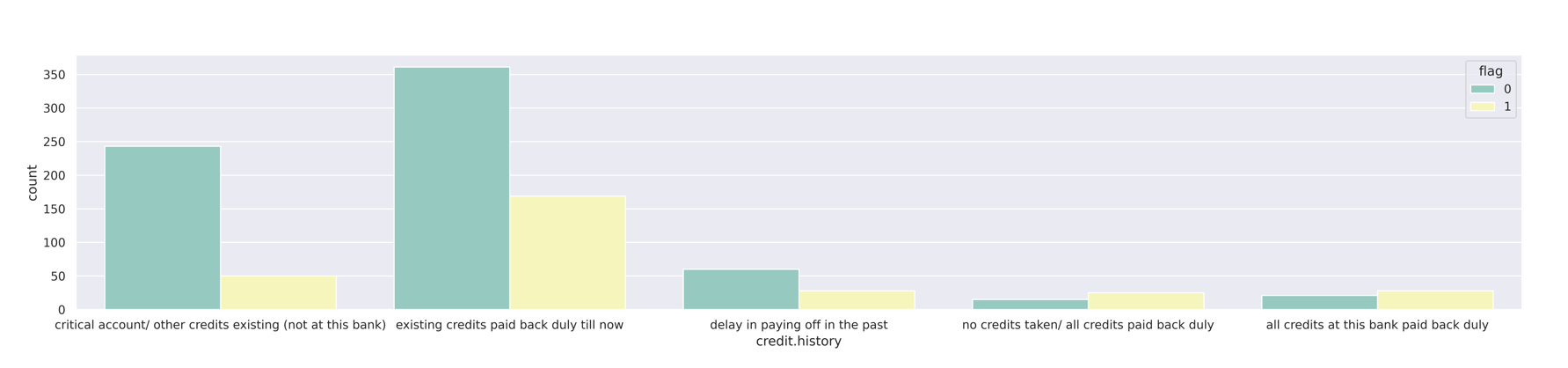
bm.visual.quick_visual.featurecategory_plot()类别型特征分布图
查看特征分布情况
bm.visual.quick_visual.featurecor_plot()相关性热图
研究两个或两个以上随机变量之间相互依存关系的方向和密切程度。
bm.eda.data_detection.DetectDF数据探查统计表
针对类别型特征计算:
1. 数值类型 2. 数据量 3. 缺失值占比 4. 唯一值个数 5. 前五个最大值 6. 前五个最小值
针对数值型特征计算:
1. 数值类型 2. 数据量 3. 缺失值占比 4. 唯一值个数 5. 平均值 6. 标准差 7. 最小值 8. 1%分位数,10%分位数,50%分位数,75%分位数,90%分位数,99%分位数 9. 最大值
2. 特征工程
- 数据清洗
缺失值的处理
离群点处理
噪声处理
- 数据集成
实体识别问题
冗余问题
数据值的冲突和处理
- 数据规约
- 维度规约
属性子集选择
单变量重要性
- 维度变换
主成分分析(PCA)和因子分析(FA)
奇异值分解(SVD)
- 数据变换
规范化处理
离散化处理
稀疏化处理
缺失值的处理
- 在金融风控场景,只有少数用户被标注为欺诈用户,剩下的大量用户均属于未标注用户。此时若直接将未标注用户视为白名单构建二分类器进行监督学习,会出现两个问题:
正样本和负样本的比例不均衡,正样本的数目远远大于负样本,影响分类器的算法效果。
实际情况正样本中也包含着少量负样本,属于带噪声的数据,严重影响算法学习到的特征,降低最终算法的准确率。
因此,此类场景需要使用PU bagging算法,为未标记样本打上正负标签
样例代码
logger.info("start data preprocessing >>>>>>>>>" )
estimator = LGBMClassifier(n_estimators=200, max_depth=2, learning_rate=0.1)
bc = BaggingClassifierPU(base_estimator=estimator, n_estimators = 30, n_jobs = -1, max_samples = len(credit_data[credit_data['flag']==1]))
bc.fit(credit_data[numeric_feats], credit_data['flag'])
score_arr = bc.oob_decision_function_[:,1] # 使用训练集的袋外估计计算的决策函数。 正样本数据点,也许还有一些未标记的数据点,在bootstrap过程中被遗漏了。 在这些情况下,`oob_decision_function_` 包含 NaN。
credit_data['score_pb'] = score_arr
credit_data = credit_data[(credit_data['score_pb'].isna()) | (credit_data['score_pb']<0.9)] # score_pb是数据属于正样本的概率
logger.info('PUbagging恢复了%s个负样本:' %len(credit_data[(credit_data['flag']==0)]))
logger.info('恢复后的数据共有%s个样本:' %len(credit_data))
logger.info("end data preprocessing >>>>>>>>>" )
模块明细
特征粗筛:过滤法(IV+PSI)
工作内容
- 特征分箱(离散化)
关于分箱的知识,请查看 数据变换_离散化处理
- 特征筛选
关于特征筛选的知识,请查看 数据规约_维度规约_特征筛选指标 数据规约_维度规约_特征筛选方法
代码样例
# 计算IV
iv_details = cal_total_var_iv(credit_data,numeric_feats=numeric_feats,category_feats=category_feats,target='flag',max_interval=10,numeric_method='chi',category_method='default')
iv_details.to_csv(os.path.join(base_dir +'/output',r'iv_details.csv'), index=False)
# WOE-IV图
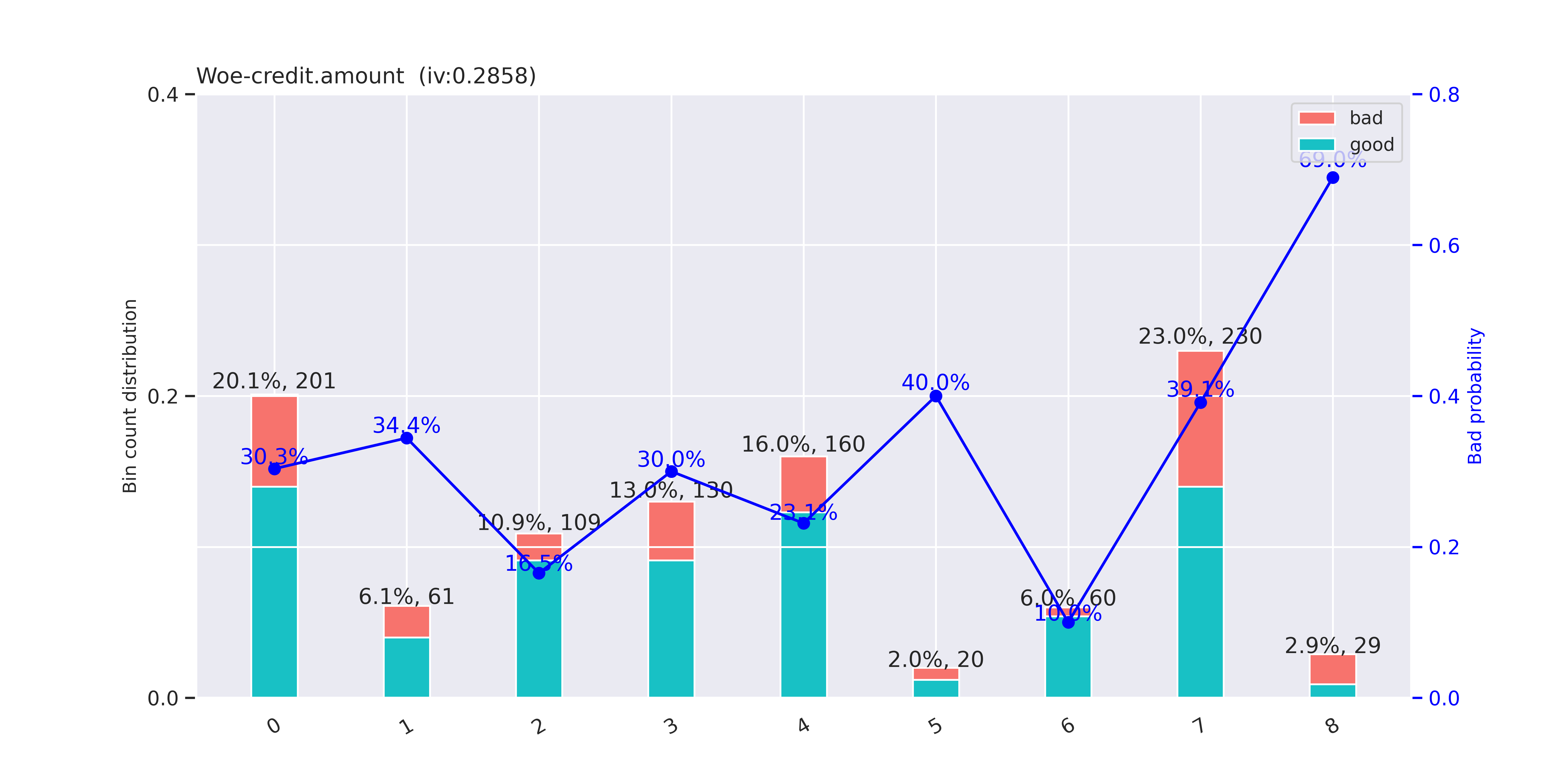
wiplot(binx=iv_details[iv_details["variable"] == "credit.amount"], title="Woe", display_iv=True,picture_name=base_dir+"/output/WOE_IV图")
# 计算psi
except_array = credit_data['credit.amount'][:500]
accept_arry = credit_data['credit.amount'][500:]
psi_df = numeric_var_cal_psi(except_array,accept_arry,bins=10,bucket_type='bins',detail=True)
psi_df.to_csv(os.path.join(base_dir +'/output', r'psi.csv'))
模块明细
bm.feature.metrics.cal_iv_psi.cal_total_var_iv()
为全量特征计算IV
可选参数:
numeric_method = ['chi', 'tree', 'distance', 'quantile', 'interpolate', 'mixed']
category_method = ['chi', 'tree', 'default']
分箱方法参数对照表
分箱方法
参数明细
适用特征
不分箱
default
类别型特征,类别数少于10
卡方分箱
chi
数值型、类别型特征
决策树分箱
tree
数值型、类别型特征
等宽分箱
distance
数值型特征
等频分箱
quantile
数值型特征
插值分箱
interpolate
数值型特征
混合分箱
mixed
数值型特征
分箱的好坏可以用WOE-IV图来评估
bm.feature.metrics.cal_iv_psi.numeric_var_cal_psi()
为某一特征计算PSI
特征细筛:嵌入法(特征重要度计算)
工作内容
空缺值过滤
单一值过滤
共线性(相关性)特征过滤
计算特征重要性,筛选有效特征
代码样例
# 特征筛选
logger.info("start featuring selection >>>>>>>>>" )
fs = FeatureSelector(data=credit_data,
target='flag',
base_features=numeric_feats+category_feats,
category_features=category_feats)
fs.identify_all(config = CONFIG)
# 特征重要性可视化
select_data, importance_feats, features_name = fs.filter_results()
select_data.to_csv(os.path.join(base_dir +'/output', r"selected_training_data.csv"), encoding='utf-8')
logger.info("end featuring selection >>>>>>>>>" )
模块明细
bm.feature.selector_market.FeatureSelector
本模块涉及配置文件的修改,详细内容请参考 配置文件
3. 算法选型+模型评估
样例代码
training_data = pd.read_csv(os.path.join(base_dir +'/output', r"selected_training_data.csv"), encoding='utf-8', index_col=0)
trn_x, tes_x, _, _ = train_test_split(training_data, training_data['flag'], test_size=0.2)
# 模型初始化
select_numeric_feats = training_data.select_dtypes(include=['int64','float64']).columns.tolist()
select_numeric_feats.remove("flag")
select_category_feats = list(set(training_data.columns) - set(numeric_feats + ['flag']))
select_base_feature = select_numeric_feats + select_category_feats
target = "flag"
model = Model(param_dict=CONFIG['lgb_params'], numeric_feature=select_numeric_feats, category_feature=select_category_feats)
pipe_model = model.make_pipeline_model(model_type='lgb')
# 准备数据
train_datas, train_targets = model.data_preprocess(datas=trn_x, base_features=select_base_feature, target=target)
test_datas, test_targets = model.data_preprocess(datas=tes_x, base_features=select_base_feature, target=target)
# 报表
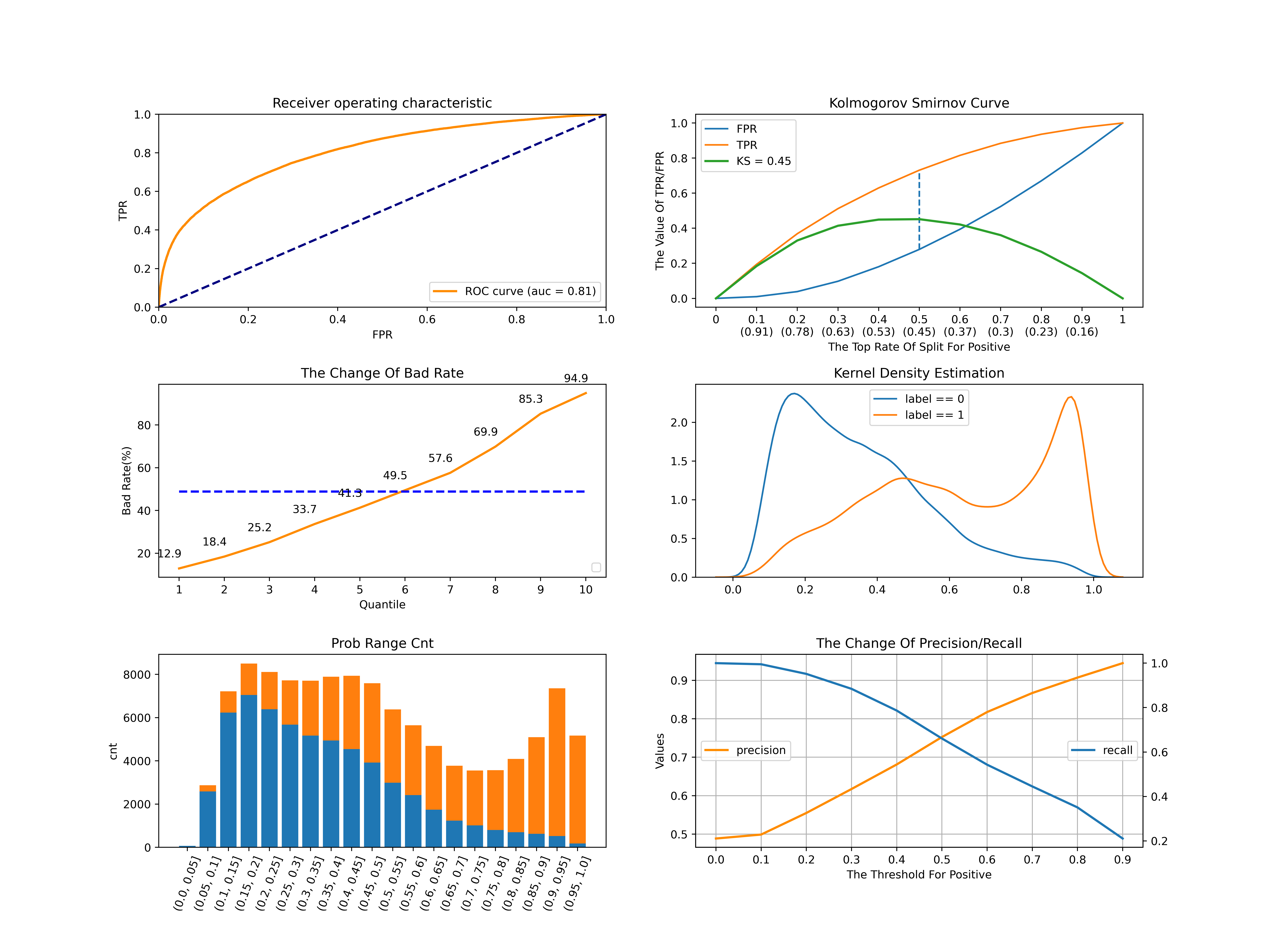
vis = reports_plot(pipe_model, X_train=train_datas, y_train=train_targets, X_test=test_datas,
y_test=test_targets, binary=True, picture_name=base_dir+"/output/报表")
logger.info("报表完成")
# 特征重要性
feature_importance_plot(importance_feats, picture_name=base_dir+"/output/特征重要性")
logger.info("特征重要性图完成")
# shap
shap_plot(vis.estimator, train_datas,all_feature_names, picture_name=base_dir+"/output/shap_force", mode="force")
shap_plot(vis.estimator, train_datas,all_feature_names, picture_name=base_dir+"/output/shap_summary", mode="summary")
logger.info("shap图完成")
模块明细
- 本模块目前支持三类机器学习模型
LightGBM分类器
XGBoost分类器
voting(集成学习)分类器
本模板涉及配置文件的修改,详细内容请参考 配置文件
模型评估报表
详细解读请参考 模型评估
4. 模型可解释性
force_plot(单样本特征影响图)
下图展示了每个特征都各自有其贡献,将模型的预测结果从基本值(base value)推动到最终的取值(model output);将预测推高的特征用红色表示,将预测推低的特征用蓝色表示
由于 Treeshap 是对对数几率(log odd ratio)进行解释,所以出现负数。
具有负向影响的变量变为 x0_co-applicant 和 x3_no checking account 等,
具有正向影响的特征变量加入 credit.amount, duration.in.month, installment.rate.in.percentage.of.disposable.income
其他变量的 Shapley Value 由于值太小就不一一列举。

summary_plot(多样本特征影响图)
summary plot 为每个样本绘制其每个特征的SHAP值,这可以更好地理解整体模式,并允许发现预测异常值。每一行代表一个特征,横坐标为SHAP值。一个点代表一个样本,颜色表示特征值(红色高,蓝色低)。
比如,这张图表明credit.amount特征较高的取值会提高的信用卡审批通过的概率

特征重要性图
传统的importance的计算方法效果不好,SHAP提供了另一种计算特征重要性的思路。
取每个特征的SHAP值的绝对值的平均值作为该特征的重要性,得到一个标准的条形图(multi-class则生成堆叠的条形图)
在特种重要性图中,status.of.existing.checking.account 该特征最重要,其次是 credit.amount,duration.in.month