模型评估
模型报表为以下六幅子图组成:
ROC-AUC曲线
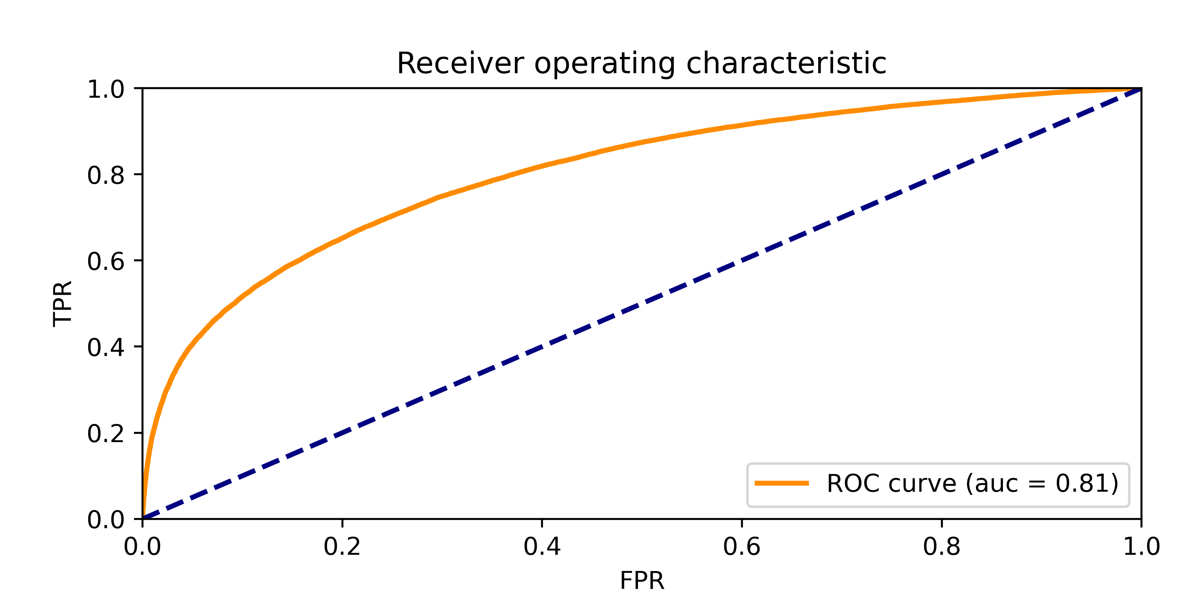
- 横坐标含义
假正率(预测为正但实际为负的样本占所有负例样本的比例)
- 纵坐标含义
真正率(预测为正且实际为正的样本占所有正例样本的比例)
- 关键信息
- ROC曲线
- 直观理解
在一个二分类模型中,假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。<br>随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。
判断标准:
ROC值一般在0.5-1.0之间。值越大表示模型判断准确性越高,即越接近1越好。 ROC=0.5表示模型的预测能力与随机结果没有差别。
- 关键信息
- AUC面积
- 直观理解
AUC(Area under curve)即ROC曲线是下的面积,它反应的是模型的排序能力,AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
判断标准:
AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。 AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。 AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
KS曲线
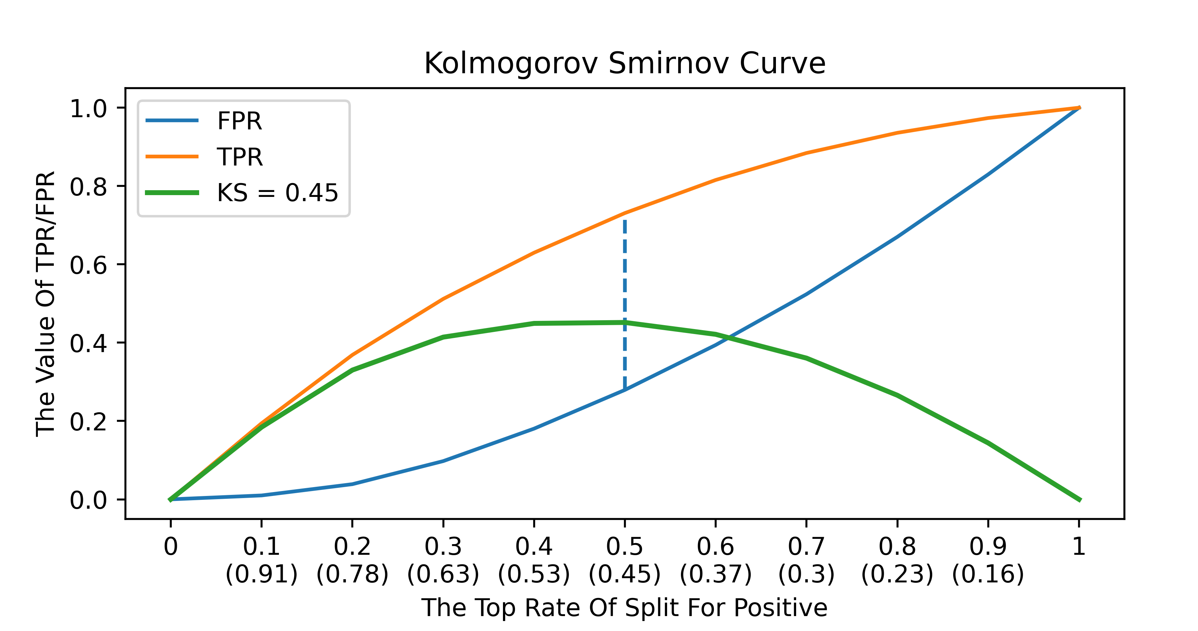
- 横坐标含义
假正率(预测为正但实际为负的样本占所有负例样本的比例)
- 纵坐标含义
真正率(预测为正且实际为正的样本占所有正例样本的比例)
- 关键信息
- KS值,划分为正样本的得分阈值
- 直观理解
KS值是MAX(TPR - FPR),即两曲线相距最远的距离。两条曲线之间之间相距最远的地方对应的阈值,就是最能划分模型的阈值。
判断标准:
KS: <20% : 差 <br>KS: 20%-40% : 一般 KS: 41%-50% : 好 KS: 51%-75% : 非常好 KS: >75% : 过高,需要谨慎的验证模型
提升度曲线
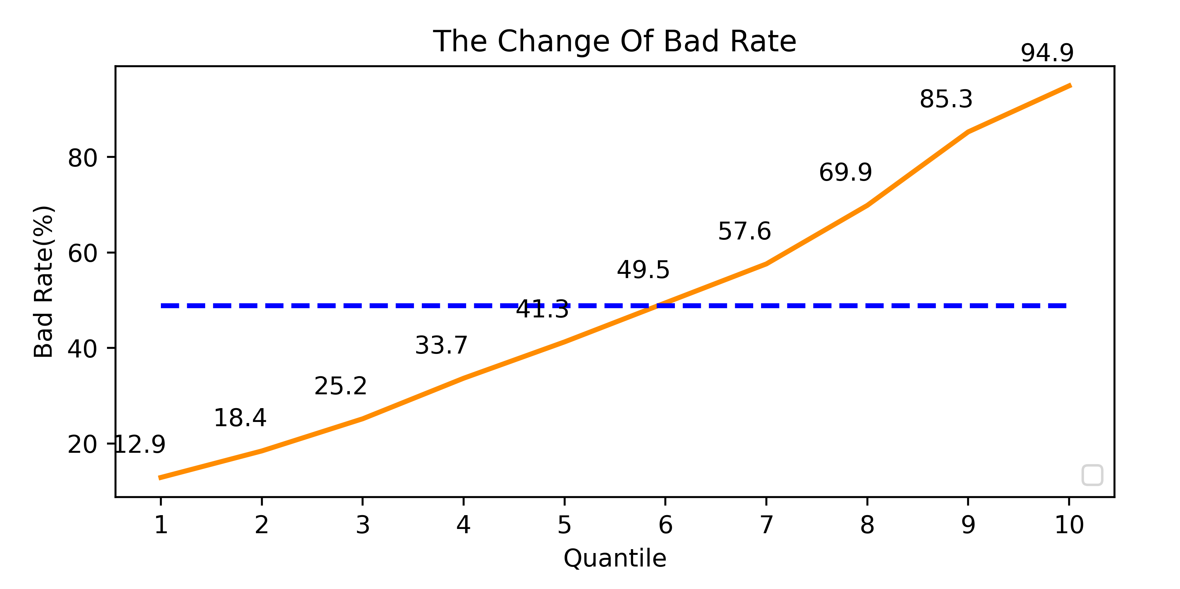
- 横坐标含义
把预测结果按得分高低分成的10组
- 纵坐标含义
每一组中正样本的比例
- 关键信息
- 提升度
- 直观理解
提升度可以衡量使用这个模型比随机选择对坏样本的预测能力提升了多少倍。举个例子,一个贷款产品目标客群有10000个人,其中混合了500个坏客户。如果随机选择1000个人放款,可能会遇到50个坏客户。但是如果运用模型对坏客户加以预测,只选择模型分数最高的1000人放款,如果这1000个客户表现出来最终逾期的只有20户,说明模型在其中是起到作用的,此时的提升度就是大于1的。如果表现出来逾期客户超过或等于50个,提升度小于等于1,那么从效果上来看这个模型用了还不如不用。提升度就是这样一个指标,可以衡量使用这个模型比随机选择对坏样本的预测能力提升了多少倍。
判断标准:
蓝色虚线表示样本整体的坏样率 黄线实线表示各个分组内的坏样率 黄色实线在蓝色虚线下的数据点,都是提升度大于1的分组
核密度曲线
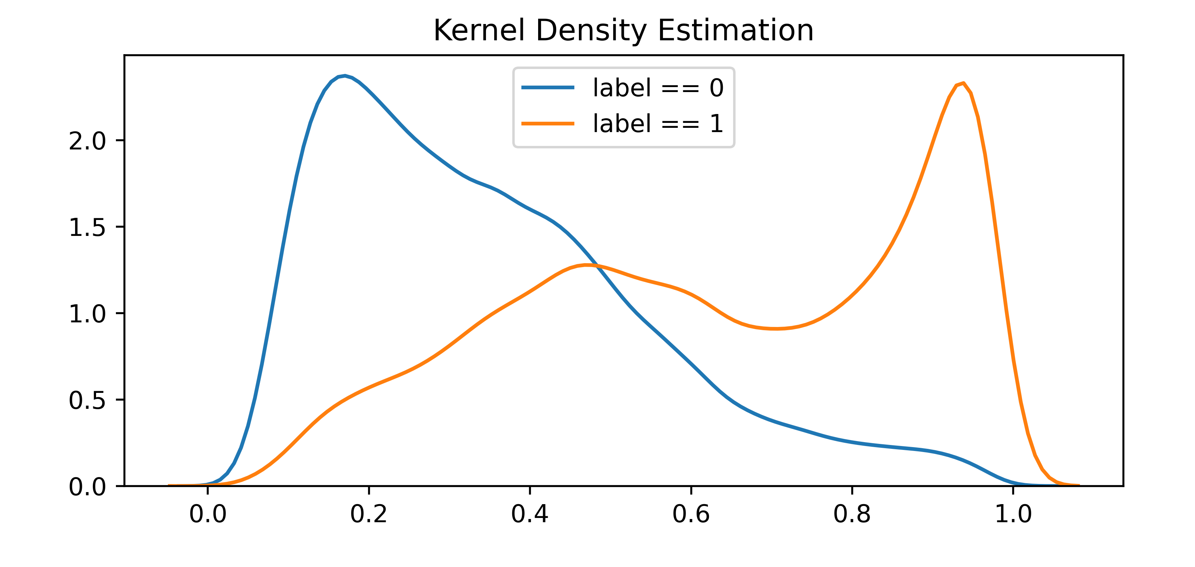
- 横坐标含义
模型的预测得分
- 纵坐标含义
某得分下数据出现的次数,通过核函数做归一化
- 关键信息
- 模型预测变量的概率密度分布
- 直观理解
核密度图可以看作是概率密度图,其纵轴可以粗略看做是数据出现的次数,与横轴围成的面积是一,曲线中,“峰”越高,表示此处数据越“密集”。
判断标准:
可以从图上直观地看到,负样本的概率密度分布和正样本的概率密度分布被明显地区分开,说明模型对正负样本有较强的区分能力
概率范围计数
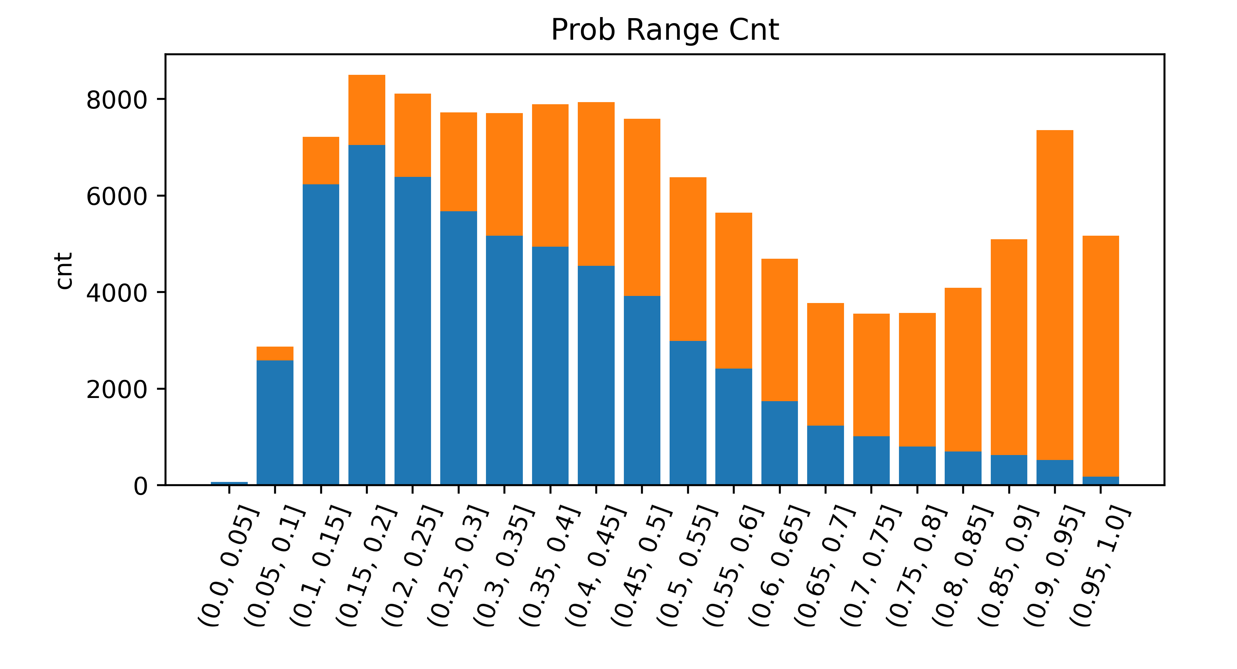
- 横坐标含义
模型预测的得分区间
- 纵坐标含义
对应得分区间下数据出现的次数
- 关键信息
- 划分为正样本的得分阈值
- 直观理解
模型预测的得分在不同得分区间下的分布情况,蓝色表示负样本,橙色表示正样本
判断标准:
可以直观地看到,当阈值位于某个区间内,正负样本能否被成功区分
精确度召回率变化曲线
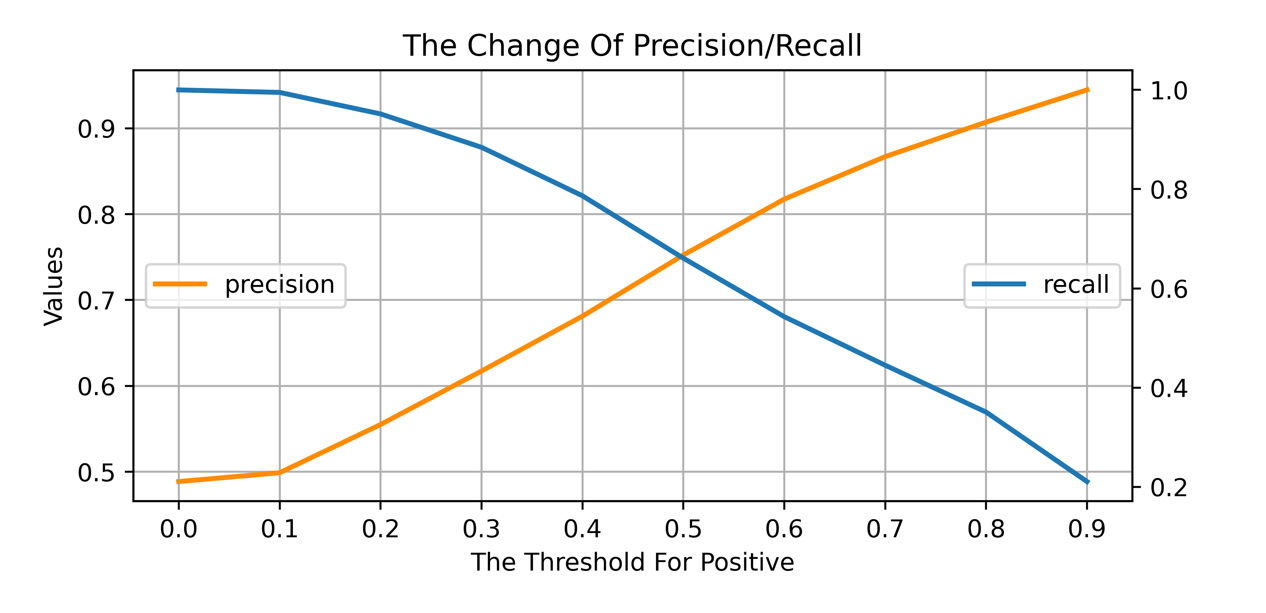
- 横坐标含义
划分为正样本的得分阈值
- 纵坐标含义
精确度/召回率
- 关键信息
- 划分为正样本的得分阈值
- 直观理解
随着阈值的增大,模型的精确度提升,召回率下降
判断标准:
在精确度和召回率同时最优的前提下,取正样本的最优划分阈值